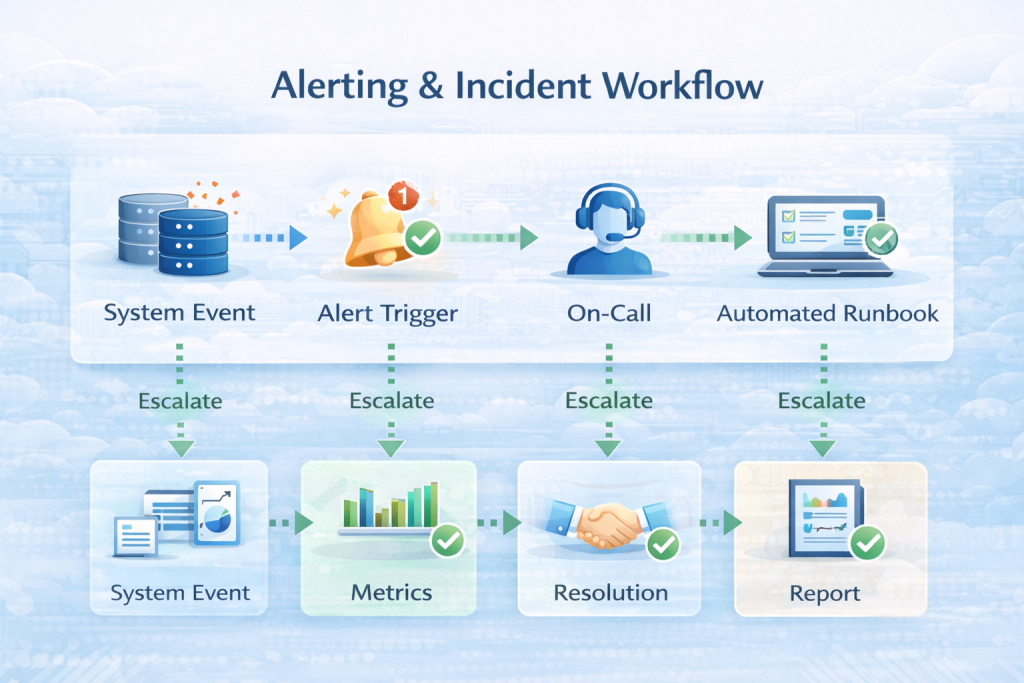
Observability is the ability to understand the internal state of a system based on emitted signals (logs, metrics, traces).
Monitoring tracks these signals to detect, alert, and respond to system events.
Together, they help teams:
 Detect anomalies early Diagnose root causes Reduce mean time to resolution (MTTR) Improve uptime and performance
Detect anomalies early Diagnose root causes Reduce mean time to resolution (MTTR) Improve uptime and performance
In 2026, observability is critical for cloud-native environments, microservices, distributed architectures, and AI-driven automation.
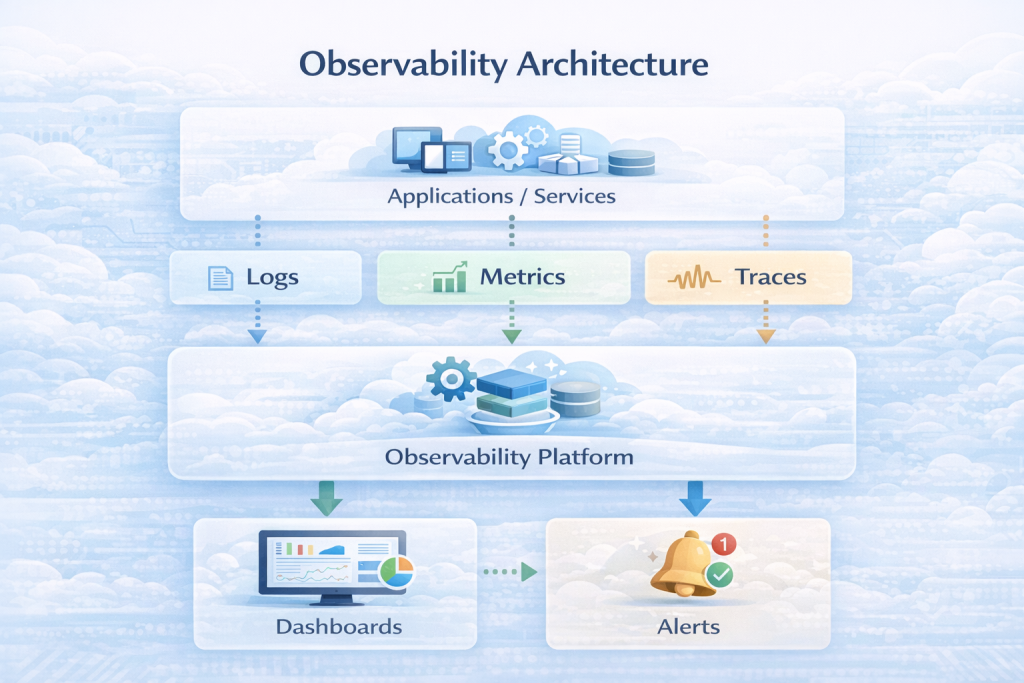
Modern systems are dynamic and distributed — spanning cloud, containers, serverless, and APIs. Without robust observability:
Issues remain undetected until they impact users
Performance bottlenecks are hard to isolate
Deployments carry unknown risk
Operations lack predictive insights
Google’s 2026 search updates prioritize content that helps teams solve real operational questions — this page is structured to directly answer those queries.
With real-time observability and analytics:
Teams get actionable insights, not just dashboards Monitoring becomes preventive, not reactive Alert fatigue is reduced through intelligent tuning Reliability becomes measurable